I recently contributed to an ongoing series called Ask Women in Product by answering this question: “When and How do I Add Machine Learning to a Product Roadmap?” Originally published in the September 17, 2019 edition, what follows is my answer in full. Thank you to @mdy for editing this piece!
While working as a global product manager at Agilent, I became enamored with advanced statistics and its business applications during my MBA at UCLA Anderson, where I studied modeling and prediction with Dr. Richard Stern and One-to-One Marketing and Marketing Research with Dr. Anand Bodapati. When I later worked as an Engineering instructor and Developer, I sought best-practice insights from Machine Learning (ML) Product Management practitioners to understand how ML is utilized in building applications.
Now that I’ve returned to product management work, I have integrated these experiences into a far better understanding of how to work ML into product roadmaps and into any applications I might build. Here’s what I’ve learned and I hope you find it helpful as well.
Table of Contents
Introduction
— What is Machine Learning?
— Artificial Intelligence > Machine Learning > Deep Learning
When is a Machine Learning-based solution appropriate?
— Problems that are well suited for ML-based solutions
— Problems that don’t need ML-based solutions
What do I need to succeed?
How do I fit Machine Learning into my roadmap?
— 1. Understand the business need
— 2. Formulate the problem hypothesis
— 3. Define clear measures of success
— 4. Assess your candidate projects
— 5. Confirm that you have the data you need to succeed
— 6. Establish healthy data collection practices
— 7. Tackle the risks and challenges
— 8. Expect to iterate
Conclusion
Resources and References
Introduction
Are you looking for ways to improve personalization, natural language processing (NLP), or search customization? Machine Learning (ML) could be the tool you need. This article will describe what Machine Learning is, what problems it can solve for you, and how to incorporate this toolkit into your product roadmaps. More importantly, this article also explains when machine learning is not the right tool for the job.
Note: There are several steps needed to take Machine Learning from concept to execution, including data preparation, model development, and the actual deployment processes. While product managers need to be actively involved in these stages, these are topics that — for now — are outside the scope of this article.
What is Machine Learning?
Arthur Samuel, a pioneer of AI research, provides us with a concise definition: “Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed.” Where traditional programming requires us to provide data and rules to generate answers, Machine Learning requires us to provide desired answers and data to generate rules.
In academics, Machine Learning is a subset of Data Science, the study of data which involves developing methods of recording, storing, and analyzing data to effectively extract useful information.
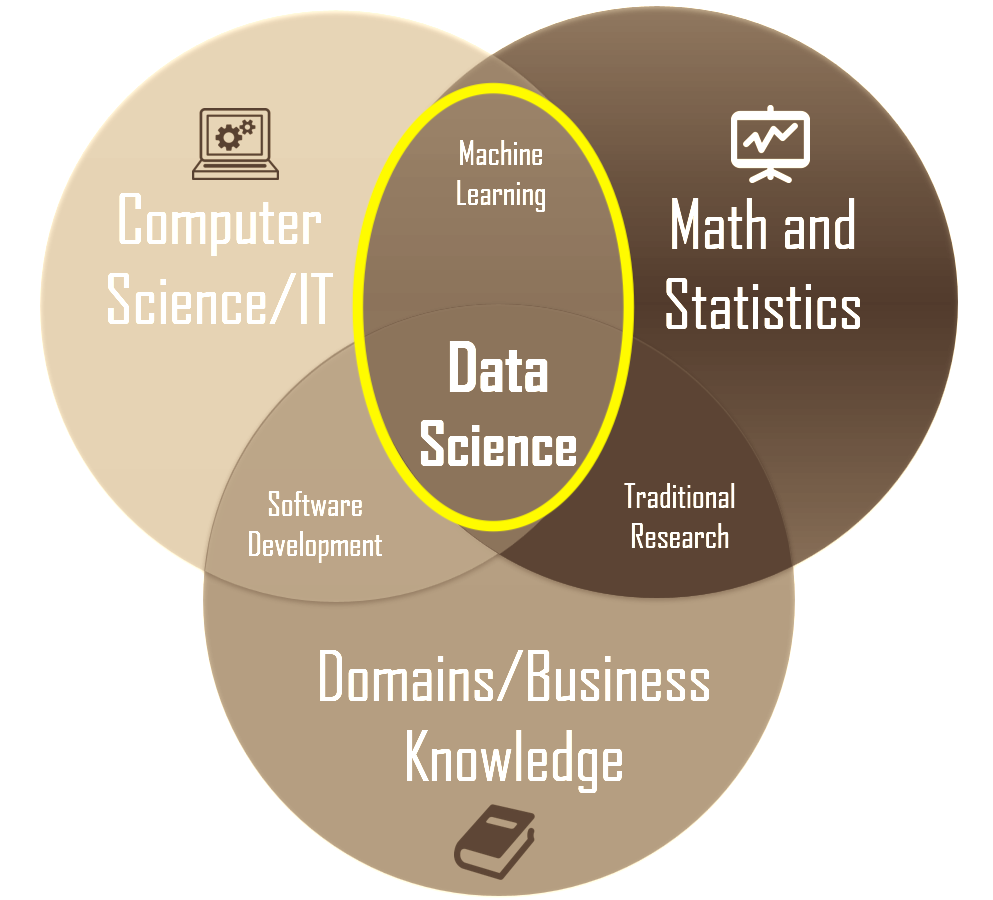
Image credit: https://towardsdatascience.com
Artificial Intelligence > Machine Learning > Deep Learning
Machine Learning (ML) is sometimes confused with Artificial Intelligence (AI) and Deep Learning (DL), which are related but differentiated. Whenever a machine completes tasks based on a set of stipulated rules that solve problems (i.e., algorithms), such an “intelligent” behavior is what is called Artificial Intelligence and includes ML and DL. ML is a subset of AI, and DL is a subset of ML. The progression from AI through DL generally represents more human-independent rule definitions and, as such, require more and more data. The diagram below shows where ML and DL fall within the AI discipline.
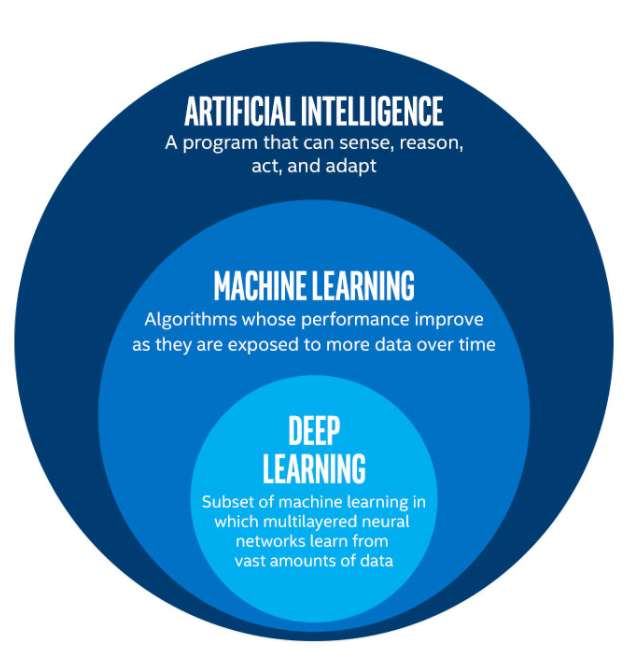
Image credit: https://blog.stateofthedapps.com/
When is a Machine Learning-based solution appropriate?
Problems that are well suited for ML-based solutions
Good use cases for Machine Learning include problems that require personalization, ranking, classification, regression, clustering, or identifying anomalies. Note that the type of problem you want to solve will drive the choice of algorithm to use (e.g. for clustering, you would use k-means).
In general, for Machine Learning to make sense for a business, your problem should have these characteristics:
- Requires complex logic that’s impractical to solve with human-defined rules, or heuristics. For example, search engines often have multiple phases of ranking that happen in series, such as initial retrieval, primary ranking, contextual ranking, and personalized ranking. This is a great application for Machine Learning.
- The problem will be scaling up very fast. If you expect that your problem will scale to thousands of users or more, then it could be a good use case for ML. Let’s say you have an online retail platform and expect to have thousands of customers avail of your new offer within three to six months. Retail customer expectations being what they are, you need a personalized experience and could give a good justification for ML.
- Requires personalization at scale. Unless you can reduce the complexity of the problem space by, for example, creating solutions for a particular segment or category rather than for each individual, you’re better off using ML to define the rules you use.
- Require rules that change quickly over time. If your rules generally remain static year after year, then a heuristic solution is preferred. However, if your business’s success depends upon quick adaptation and rule changes, then ML is a good route. For example, if you have a search product and Ed Sheeran drops a new album, your algorithm needs to adapt in real-time and is amenable to an ML solution.
- Has a known, pre-defined end result. For example, in online retail, you want your model to provide recommendations which result in a sale. In search, typing “shirt” should return results with lists of shirts that are most likely to lead to a purchase.
- Does not require 100% accuracy. If business success can be achieved with a high probability of accuracy rather than with perfection, then ML is a good option. For example, recommendation systems will not be considered faulty if users don’t always want what is served. Users can still have a great experience and the program can learn from the lack of sales to deliver improved recommendations in the future.
Problems that don’t need ML-based solutions
Some features of Google’s Gmail are great examples of when a heuristic-based solution is preferred. In the screenshot below, Gmail looks for phrases including words like “attachment” or “attached” to pop up a reminder when someone may have forgotten to attach a file. Although an ML system would most likely catch more potential mistakes, it would be far more costly to build. The heuristic solution provides good user experience and allows organizational resources to be used for more impactful projects.
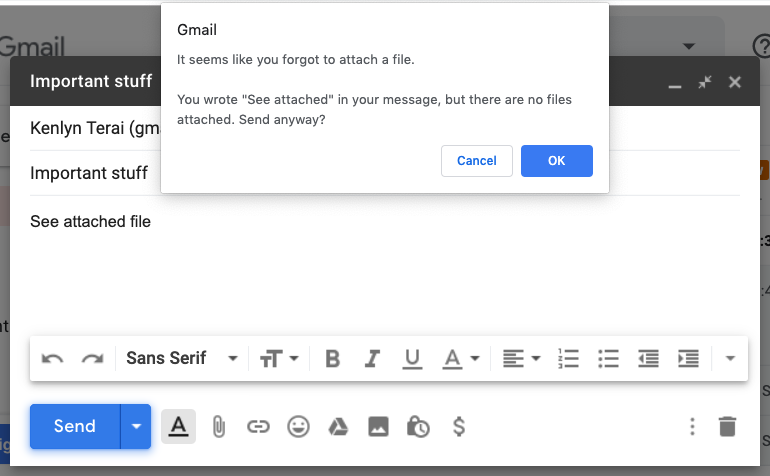
A successful heuristic-based solution (Image by Google/Gmail)
What do I need to succeed?
A successful Machine Learning project needs the following:
- A clearly defined business problem. Machine Learning shifts engineering work from a deterministic process to an experimental one, so there is an even greater need to know what you want to achieve upfront.
- The right team. You’ll need a team with skills in both Data Science and Engineering. In Data Science, roles can include an ML Scientist, Applied Scientist, Data Scientist, and/or Research Scientist. In Engineering, roles can include a Business Intelligence Engineer, Data Engineer, Software Engineer, Development Manager, and/or Technical Program Manager.
- A grasp of the project’s potential risks and returns. Even if a project is feasible from an ML perspective, the level of effort needed to develop and maintain an ML-based solution may make such an approach impractical. For example, if your model needs to be updated very frequently in production, to the point where it requires a lot of maintenance, it may not be worth it.
- Enough data. You need at least thousands of rows of data for linear models and hundreds of thousands of rows for a neural network. If you don’t have the data, you’ll need strategies to acquire it, and may need to stick to heuristic-based approaches until you do.
- Data with a clear pattern. Since algorithms require patterns to learn from, you need to have a sense of what patterns exist in your data, even if you don’t know the precise pattern before you get started. You should be able to articulate these patterns qualitatively or have a gut feeling at the minimum.
- High-quality data. As the adage goes, “garbage in, garbage out.” Lean on your Data Scientists to help you determine your data’s status and/or how to acquire data that is:
1. sufficient in completeness and simplicity
2. relevant to the problem that you are solving
3. recent, reflecting users’ current behaviors
4. representative of the segment and timeframe you‘re addressing
5. unbiased
6. respectful of user privacy and is secure - The right technologies. There are several open-source tools and platforms, such as Amazon AI, TensorFlow (originally developed by Google), and many others that make machine learning accessible to virtually any company today.
How do I fit Machine Learning into my roadmap?
While the specific details may vary from one project and company to another, these are the general steps that you’d need to consider.
1. Understand the business need
Start by avoiding the mistake made by many companies and product teams: don’t jump right into product strategies that start with Machine Learning as a solution and skip right to focusing on a meaningful problem to solve.
Machine Learning, like heuristics, is just another tool for solving human needs. If you and your stakeholders aren’t aligned on the business need, you’re just going to build a very powerful (and expensive) system that isn’t meaningful to your customers or your business.
2. Formulate the problem hypothesis
For each of the business needs identified in the preceding step, formulate and document the hypothesis that you intend to test. In general, your hypothesis statement will have the following parts:
- A change that you are testing (“Improving the search ranking with ML will…”)
- A desired outcome (“… allow our customers to find the correct product…”)
- Success metrics (“…in 15% less time.”)
- A description of the Model’s output (“The model will score each possible product…”)
- Predictors (“…by using products recently viewed by the customer, the types of products previously purchased, the monetary value of previous purchases, and our own understanding of what products are frequently brought together …”)
- Target (“…to predict the product that the customer ultimately selects for purchase.”)
3. Define clear measures of success
What does success look like if we were to solve the problem and meet the business need? You and your stakeholders need to get to a shared understanding of what that means, based on the problem hypothesis.
For example, do you expect certain performance indicators to move? Do you expect new business opportunities to be unlocked? In practical terms, are we talking about an increase in gross revenue? Improved targeting of marketing offers leading to a lower average cost for each newly-acquired customer? Increased customer satisfaction through an interactive, ML-based self-help system?
The more you can express success in terms of actual targets, the easier it will be for your team to stay focused and prove the business benefits of the ML effort.
4. Assess your candidate projects
With a defined business need, customer problems to solve, and a clear measure of success, assemble a team of UX/UI professionals, ML experts, and data scientists early in your roadmap definition process.
Create a 2×2 matrix that plots the impact and the effort needed for each candidate project, prioritize work with the highest impact/lowest effort, then rank product ideas by ROI as you iterate on features or projects to prioritize.
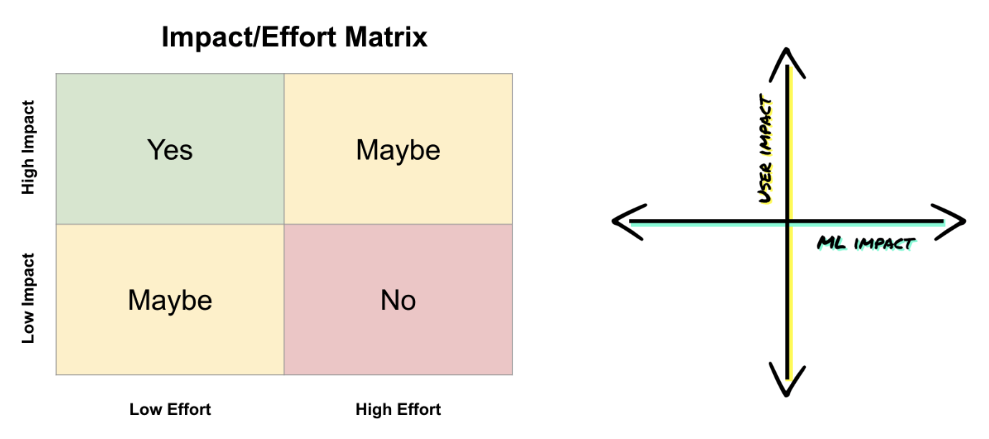
Left: Impact/Effort Matrix (created by the author). Right: User Impact/ML Impact matrix (Image credit: Google)
Only high-impact products should be considered for an ML project. At Google, for example, teams can vote on which ideas could have the biggest user impact and which would be most enhanced by an ML solution, prioritizing those ideas which deliver a high impact for both. If there are several candidates, then plotting these ideas on a matrix of user impact vs. ML impact (i.e. impact on product improvement) can help you choose your project.
5. Confirm that you have the data you need to succeed
Evaluate your team’s data needs and whether the available data meets the criteria set forth in the previous section. ML models require a lot of data, are complex, and can take a long time to develop and test before achieving production-readiness.
You may discover that you don’t have enough data but you can see the need for an ML solution in your future. In this scenario, you will be better off launching a traditional MVP with simple heuristics to pave the way for developing an ML model. This is an excellent opportunity to establish a set of baseline data for your product. In this scenario, you’ll want to establish success metrics and design your system with metric instrumentation in mind.
If it turns out that you do have the data that you need, you’ll want to ensure that the system you want to improve with ML is receiving the data you want and is instrumented to collect your metrics of interest. You’ll also want to A/B test your current system against the ML model. At the minimum, your v1.0 ML model should maintain your current level of user satisfaction and other metrics.
6. Establish healthy data collection practices
With regards to the actual task of data collection, here are some excellent recommendations on how to gather quality and standardized data from users, based on Peter Skomoroch’s recent Strata Data Conference presentation.
- Guide user input when you can
- Use auto-suggest fields
- Validate user inputs, emails
- Collect user tags, votes, and ratings
- Track impressions, queries, and clicks
- Sessionize logs
- Disambiguate and annotate entities (company names, locations, etc.)
As your user base grows, heuristics become burdensome. As you acquire enough data to begin an ML project, you’ll be in a good position to not only develop a model but also to A/B test your ML model against your heuristics.
7. Tackle the risks and challenges
ML projects come with their own sets of risks and challenges. You’ll want to address these risks head-on to keep your project on track.
- Be aware of the types of bias that might impact your model. Mitigate these biases by allowing your model to measure them, then take steps to counteract the biases.
- Be aware that seemingly small UI changes may result in significant backend ML engineering work that may put the overall project at risk. For example, if the wording of a question is changed in your website or app, it can change the response from users and render your historical data useless. Be fully aware of the impact of any recommended changes, A/B Test, and get user feedback!
- Even with the right data, you may still not end up with a working model. For example, if your model overfits the training data, over-learning the data’s details and noise, the model will fail to make correct predictions on new data. Data scientists can address this by “regularizing” the model.
- Asking for too much user data without any visible benefit can cause the user to abandon your product. Provide value to your users as early as possible before asking them for more data.
- You need to have the appropriate security and privacy precautions in place any time your model includes or relies on personal data. Proactively consult with your company’s legal, safety, and security teams for advice in this area.
8. Expect to iterate
Once your model is deployed, continue to iterate and improve on it. Easily 80% of the work happens after the first version of an ML model is shipped to production. This work includes model improvements as well as adding new signals and features into the model as more data becomes available and new insights come to light.
Conclusion
Machine Learning provides massively scalable solutions for recommendations, ranking, classification, anomaly identification, and more. Experimental in nature and time-consuming, ML projects require clear goal definitions and measures of success for evaluating the end results that are expected from your ML model.
As a PM, expect to manage stakeholder expectations around project objectives and deliverables, make prioritization tradeoffs, and ensure that the right data is selected for your model. Above all, expect to iterate, because the initial launch is just the first step in a complex, challenging, and rewarding journey.
Resources and References
- Harvard Business Review, If Your Data Is Bad, Your Machine Learning Tools are Useless
- Google Developers, Rules of Machine Learning, Best Practices for ML Engineering by Martin Zinkevich
- Product School, Machine Learning for Product Managers by Ruben Lozano-Aguilera
- Machine Learning Product Management: Lessons Learned by Ann Spencer
- How to Deploy Machine Learning Models by Christopher Samiullah
- A Veteran Data Scientist’s Perspective: Managing your First Data Science or Machine Learning Project by Paul Sheets
- Google Design, Human-Centered Machine Learning
- Towards AI, The 50 Best Public Datasets for Machine Learning by Stacy Stanford and Roberto Iriondo





































































